Database design
I'm going to quickly go over some database design decisions - don't fret - it's pretty easy once you get the hang of it. If you're an experienced software engineer who has done noSQL schema design you'll probably know all this and can skip down to CRUD Games.
Meteor requires you to make decisions regarding all layers of the stack, which unfortunately means a little more responsibility than the average web developer is used to (have you had much experience planning database schemas?). While it's easy to start creating collections and embedding objects within objects, we have to remember that database design is profession in itself - small errors can lead to huge problems once there is a lot of data in your database; problems like slow queries and inconsistent data.
With relational databases (like MySQL, or PostgreSQL), you'd be writing out the schema - defining tables and columns with their data types. While Mongo doesn't force this kind of metadata, it can be helpful to spend some time sketching diagrams of what your database is going to look like, especially when it comes to the possibility of using foreign keys (attributes that reference the ID of other documents).
In our case we have this new collection called 'games'. Now a game has two teams. And a team can have many games. How would you model this data?
We can add a teams array to our game objects, but in this array do we include our team's names? Or do we use the team ids to look up the teams and retrieve their names?
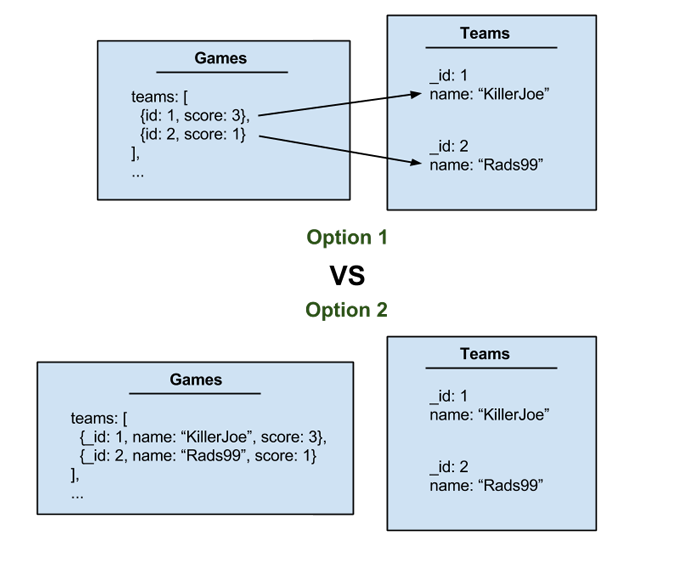
If we go with option one (use foreign keys) then how do we get the name of the teams when we print them on the page? Do we merge the two collections together somehow? Do we do this on the server or on the client?
If we go with option two (embedding the teams), then what if we change the name of a team? This would mean we'd have to find every game that team has played in and update their name.
Normalization vs Denormalization
The question of whether to use a join (foreign key) or to duplicate (embed) data is often asked, and has some terminology. Firstly we have 'normalization', which is the process of splitting common data into more and more tables or collections and using foreign keys to join them all up. This makes sense in that it stops data duplication and prevents data anomalies that can arise from updating duplicate data: this is what relational databases were made for.
Secondly there is denormalization, where it is encouraged to reduce relationships between tables and embed data within each document. A good way to remember which is which is to take note that both 'denormalization' and 'duplication' start with the letter 'd'. To denormalize is to duplicate.
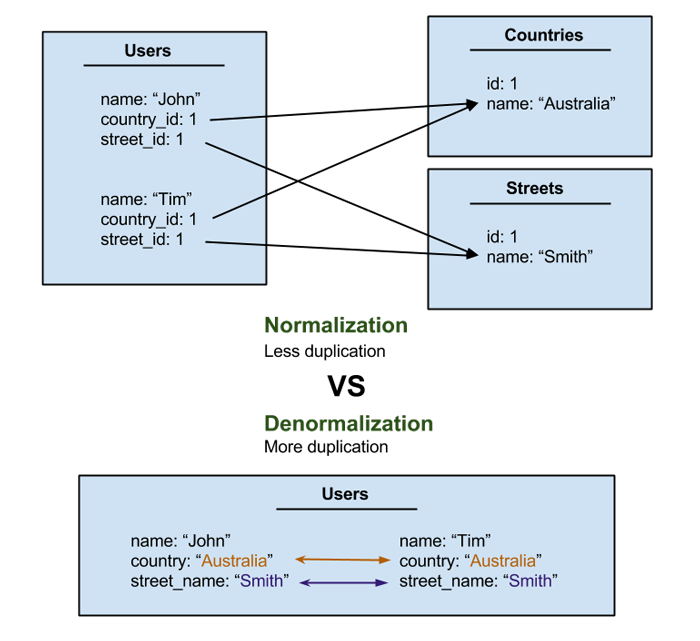
Simply by using Meteor we have made a fairly important decision in our app stack: we have decided to use a noSQL database instead of an SQL (or relational) one. Using a noSQL database comes inherent bias towards denormalization. Data is stored in JSON as rich documents, which means they can have unlimited depth (though there is a 16mb limit on each document). The ease in which to embed objects, like comments in a blog post, is alluring. Even the name for a row in noSQL - 'document' - kind of implies it is one object with everything it needs inside of it.
So where am I going with this? Well, basically I'm trying to highlight the importance of making informed decisions when it comes to questions regarding data structure. Once our database fills with more and more documents the way we structured it is going to become more and more important.
Design your schema to suit your app's data access patterns
You may have noticed that the way we design our data is tied to our app's data access patterns. For example, since we know that our games are integral to our application we should prioritise making them accessible in the database. We will often be presenting lists of games and so all the game data should be available within each game document (even if it means duplicating the team names). We know that team names won't change often so this is an acceptable trade off.
This is different to relational database design, where the schema design is more independent to the application design. The data is modelled in a way to reduce duplication and be accessible in almost any way through the use of joins. The drawback to this is that the schema it not as closely mapped to the application logic. For example, in Mongo a blog post could contain all of it's comments embedded inside it's document. However in a relational database the comments will be in their own table; you would have to gather the data for a blog post from different tables by using joins.
If your interested I found a great bunch of videos explaining MongoDB schema design on YouTube (highly recommended).
Our database design options
Here I'll present our options and go through a list of positives and negatives for each option. While it seems overkill for such a small thing, it can be applied to any database design decision - something you will have to do often as a Meteor developer.
Option 1: Don't embed the whole team object (normalize)

Positives
- no data duplication
- if you change a teams name, there will be no chance of data inconsistencies occuring
Negatives
- we will need to join games with their teams to access the team names
- listing games will be slightly slower due to the joining of data
Option 2: Embed the whole team object (denormalize)

Positives
- no need for manual joining to get the team names
- will be easy to work with in our templates
- teams will rarely change their name, so mass updates won't happen often
- games are integral to our app and will be frequently accessed - and therefore we should prioritise this data over other data
Negatives
- if a team changes its name we will have to update every single game, which will get slower and slower to do as more games are added
- data is duplicated, which increases risk of data inconsistencies (eg. imagine a team changes it's name and for some reason not every game is updated with the new name)
Option Three: Option Two plus a 'gameIds' array
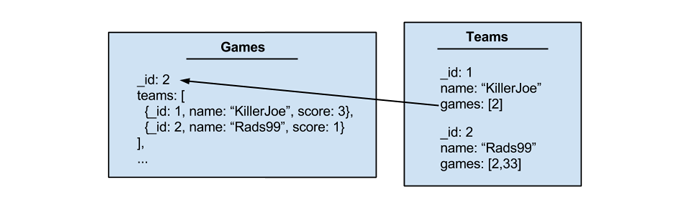
Positives
- Same positivs as option two
- When a team updates its name it will be easy to update the games it is in (because we already have a list of the game ids)
- It would also be trivial to display a list of games for a particular team
Negatives
- Creating a new game will now mean two more round trips to the database to update the teams
- Storing foreign keys in an array like this can lead to data inconsistencies if we don't keep it updated properly
The winner
As you can see there are no clear cut answers - all options will work and it's just a matter of deciding which will work best in the long run. However all things considered I'm going to go for option 3.